
الوصف
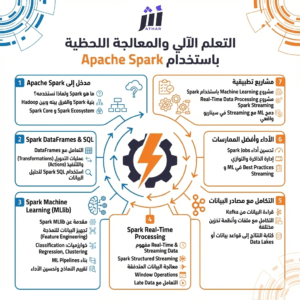
تهدف هذه الدورة إلى تمكين المتدربين من تحليل البيانات الضخمة بكفاءة باستخدام Spark SQL ضمن بيئة Apache Spark، حيث يتعلّم المشاركون كيفية التعامل مع أحجام بيانات كبيرة، وتنفيذ الاستعلامات والتحويلات بشكل موزّع، وتحسين الأداء للحصول على نتائج أسرع وأكثر دقة. تبدأ الدورة من أساسيات Spark وDataFrames، ثم تنتقل إلى كتابة استعلامات SQL على بيانات كبيرة، ودمج البيانات من مصادر متعددة، وإنشاء جداول وواجهات عرض (Views)، وصولًا إلى مفاهيم متقدمة مثل تحسين الاستعلامات، إدارة التقسيم (Partitioning)، والتعامل مع صيغ التخزين الشائعة مثل Parquet. بنهاية الدورة سيكون المتدرب قادرًا على بناء تحليلات قابلة للتوسع على البيانات الضخمة وإنتاج مؤشرات وتقارير قابلة للاستخدام.
أهداف الدورة
فهم كيف يعمل Spark في معالجة البيانات الضخمة بشكل موزّع.
استخدام Spark SQL لتحليل البيانات عبر استعلامات قوية وسهلة القراءة.
تطبيق أفضل الممارسات لتحسين الأداء وتقليل زمن التنفيذ.
بناء تدفقات تحليل (Analytics Pipelines) قابلة للتوسع على بيانات حقيقية.
ماذا ستتعلم؟
مقدمة في Apache Spark وSpark SQL وDataFrame API.
قراءة البيانات الضخمة من ملفات/مخازن مختلفة (CSV, JSON, Parquet, Hive…).
إنشاء DataFrames وTemp Views وتنفيذ استعلامات SQL عليها.
عمليات التحويل الأساسية: Filter, Select, Group By, Aggregations.
عمليات الدمج والربط (Joins) بأنواعها مع بيانات كبيرة.
التعامل مع التواريخ، النصوص، الدوال المدمجة، وUDF (مقدمة حسب المستوى).
إدارة التقسيم Partitioning وBucketing (متى نستخدمها ولماذا).
تحسين الأداء: Caching/Persist، تقليل Shuffle، فهم Explain Plan.
التعامل مع الأخطاء وجودة البيانات (Nulls, Duplicates) والتحقق من النتائج.
محاور الدورة (Outline مختصر)
مقدمة: البيانات الضخمة ولماذا Spark؟
إعداد البيئة + المفاهيم الأساسية (Cluster, Executor, Partition)
DataFrames وقراءة/كتابة البيانات
Spark SQL: Views، الاستعلامات، التجميعات
Joins وتحليلات متقدمة (Window Functions – حسب المستوى)
صيغ التخزين والأداء (Parquet/Compression)
تحسين الاستعلامات ومراقبة التنفيذ
مشروع تطبيقي: تحليل بيانات ضخمة وبناء مؤشرات نهائية
مخرجات الدورة
تنفيذ مشروع عملي لتحليل Dataset كبير باستخدام Spark SQL.
مجموعة استعلامات جاهزة قابلة لإعادة الاستخدام (Templates).
فهم عملي لتحسين الأداء في Spark وتقليل تكاليف التشغيل.
الفئة المستهدفة
محللو البيانات ومهندسو البيانات (Data Analysts / Data Engineers).
مطورو BI وETL الراغبون في الانتقال لمعالجة البيانات الضخمة.
أي شخص لديه خبرة أساسية بـ SQL ويريد توسيعها على Big Data.
المتطلبات
معرفة جيدة بأساسيات SQL.
أساسيات بسيطة في البرمجة مفيدة (Python/Scala) لكنها ليست شرطًا إذا كانت الدورة تركّز على SQL داخل Spark.

المراجعات
لا توجد مراجعات بعد.